publications
My posters, papers and publications in peer-reviewed conferences.
2025
- Poster
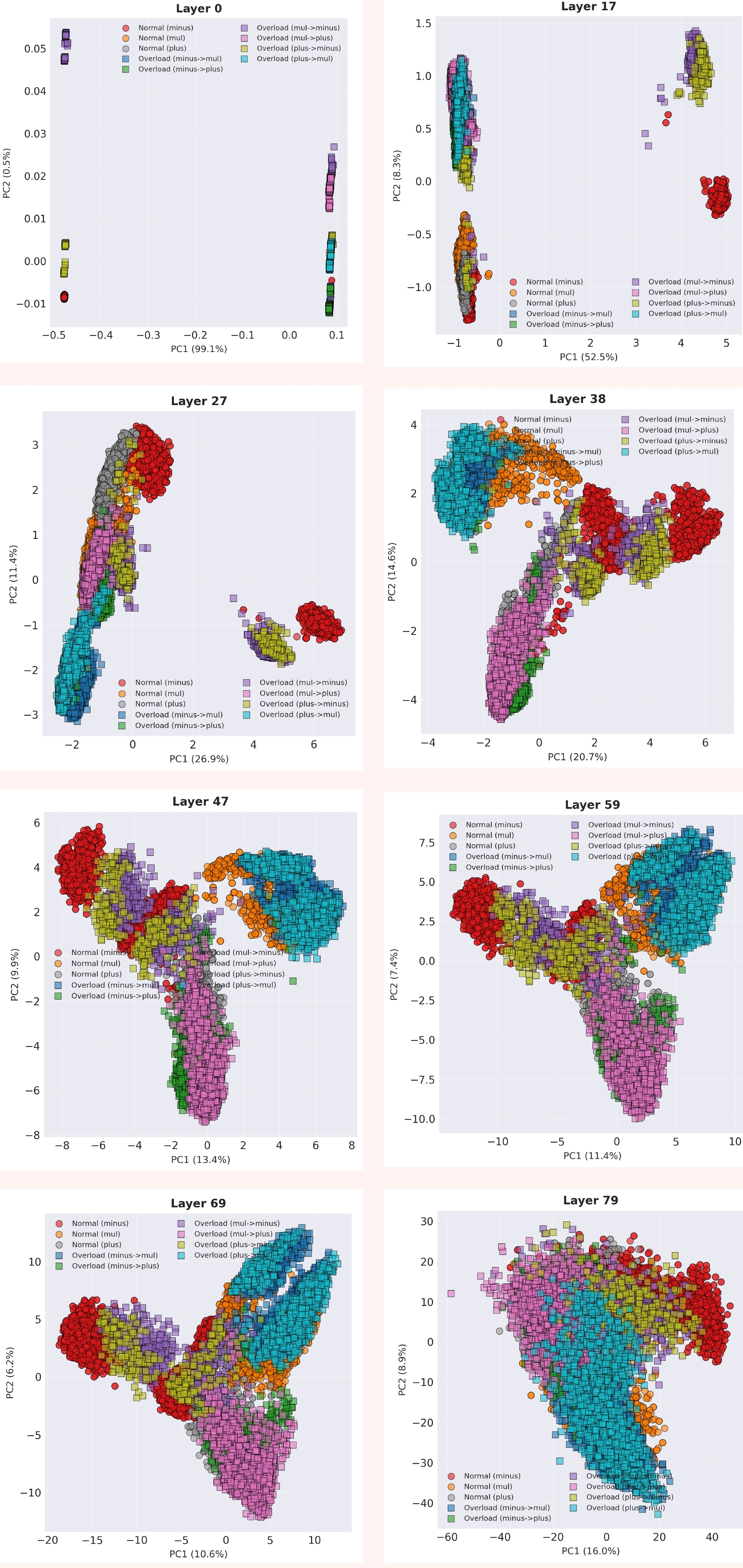 When ‘+’ Means ‘-’ – Probing Arithmetic Circuits Under Symbol RedefinitionAditeya Baral, Allen George Ajith, and Shauli RavfogelIn Poster, 2025
When ‘+’ Means ‘-’ – Probing Arithmetic Circuits Under Symbol RedefinitionAditeya Baral, Allen George Ajith, and Shauli RavfogelIn Poster, 2025Prior work shows that when LLMs perform arithmetic, they reliably use a consistent internal computation pathway, also known as a neural circuit. We investigate whether redefining operator semantics in-context causes the model to reuse the same arithmetic circuit with modified inputs, or instead activates a distinct computation pathway. Through our experiments, we analyze activation geometry, representational dynamics, and attention patterns across transformer layers. Our results reveal that while operator overloading induces temporary representational divergence in early and mid layers, the model progressively reorganizes representations to align with the target operation’s semantics in later layers. This late-stage semantic convergence, supported by selective attention reconfiguration, demonstrates that LLMs treat arithmetic operators as meaningful semantic primitives rather than purely surface-level tokens, ultimately converging onto shared semantic circuits through internal representational remapping.
@inproceedings{baral2025whenplusmeansminus, title = {When `+' Means `-' -- Probing Arithmetic Circuits Under Symbol Redefinition}, author = {Baral, Aditeya and Ajith, Allen George and Ravfogel, Shauli}, booktitle = {Poster}, year = {2025}, dimensions = {true}, } - Preprint
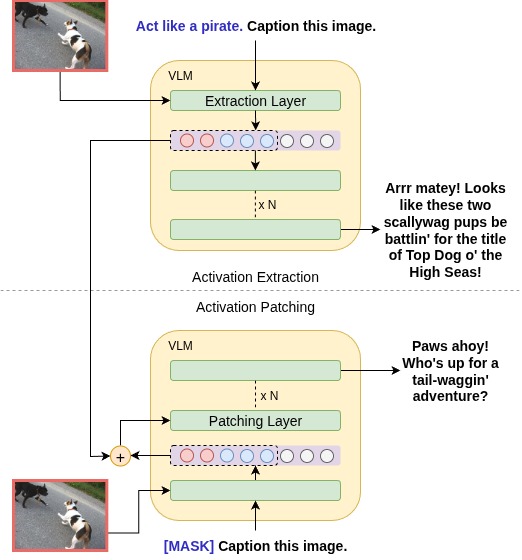 Patch and Control: Steering Behavior of Large Vision-Language Models via Latent ActivationsAditeya Baral, Dilip Venkatesh, and Rijul DahiyaIn Preprint, 2025
Patch and Control: Steering Behavior of Large Vision-Language Models via Latent ActivationsAditeya Baral, Dilip Venkatesh, and Rijul DahiyaIn Preprint, 2025We propose a novel approach to steer the behavior of Large Vision-Language Models (LVLMs) through activation patching, a mechanistic interpretability technique that modifies a model’s internal representations. By extracting latent activations from image-captioning prompts conditioned with behavioral control statements and injecting them into a separate inference pass, we enable implicit conditioning without modifying the input or fine-tuning the model. Our experiments with LLaVA-1.5 demonstrate that patched activations yield semantically coherent and controllable outputs, as measured by BLEU, BERTScore, cosine similarity, and COMET. We find that early decoder layers offer the highest fidelity for behavior transfer. These results suggest that activation patching is a viable and interpretable method for controlling LVLM outputs, shedding light on the internal mechanisms of multi-modal models.
@inproceedings{baral2025patchcontrol, title = {Patch and Control: Steering Behavior of Large Vision-Language Models via Latent Activations}, author = {Baral, Aditeya and Venkatesh, Dilip and Dahiya, Rijul}, booktitle = {Preprint}, year = {2025}, dimensions = {true}, } - Preprint
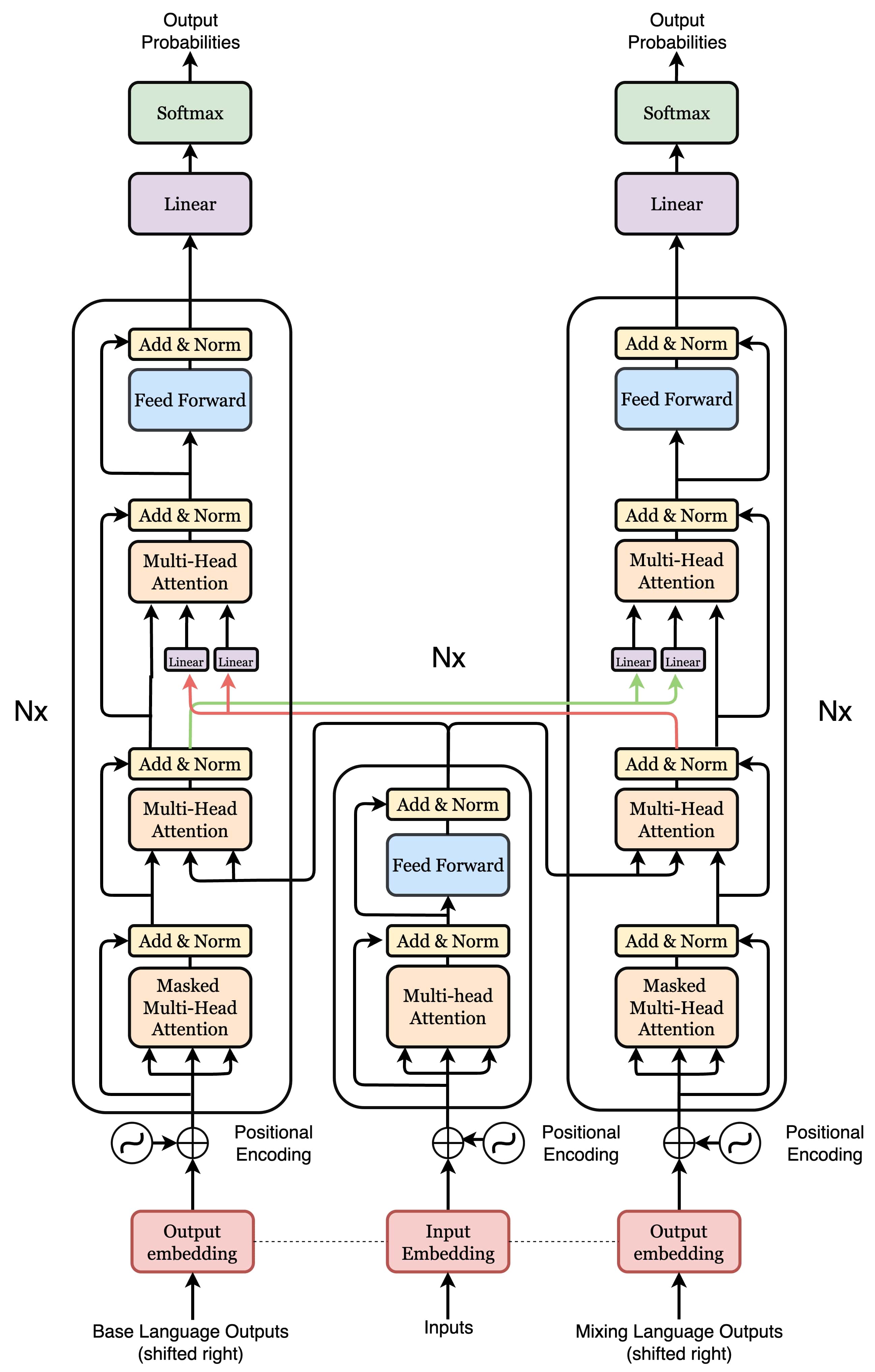 CMLFormer: A Dual Decoder Transformer with Switching Point Learning for Code-Mixed Language ModelingAditeya Baral, Allen George Ajith, Roshan Nayak, and 1 more authorIn Preprint, 2025
CMLFormer: A Dual Decoder Transformer with Switching Point Learning for Code-Mixed Language ModelingAditeya Baral, Allen George Ajith, Roshan Nayak, and 1 more authorIn Preprint, 2025Code-mixed languages, characterized by frequent within-sentence language transitions, present structural challenges that standard language models fail to address. In this work, we propose CMLFormer, an enhanced multi-layer dual-decoder Transformer with a shared encoder and synchronized decoder cross-attention, designed to model the linguistic and semantic dynamics of code-mixed text. CMLFormer is pre-trained on an augmented Hinglish corpus with switching point and translation annotations with multiple new objectives specifically aimed at capturing switching behavior, cross-lingual structure, and code-mixing complexity. Our experiments show that CMLFormer improves F1 score, precision, and accuracy over other approaches on the HASOC-2021 benchmark under selected pre-training setups. Attention analyses further show that it can identify and attend to switching points, validating its sensitivity to code-mixed structure. These results demonstrate the effectiveness of CMLFormer’s architecture and multi-task pre-training strategy for modeling code-mixed languages.
@inproceedings{baral2025cmlformerdualdecodertransformer, title = {CMLFormer: A Dual Decoder Transformer with Switching Point Learning for Code-Mixed Language Modeling}, author = {Baral, Aditeya and Ajith, Allen George and Nayak, Roshan and Bhanja, Mrityunjay Abhijeet}, booktitle = {Preprint}, year = {2025}, url = {https://arxiv.org/abs/2505.12587}, dimensions = {true}, } - Preprint
 Can LLMs understand Math? – Exploring the Pitfalls in Mathematical ReasoningTiasa Singha Roy*, Aditeya Baral*, Ayush Rajesh Jhaveri, and 1 more authorIn Preprint, 2025
Can LLMs understand Math? – Exploring the Pitfalls in Mathematical ReasoningTiasa Singha Roy*, Aditeya Baral*, Ayush Rajesh Jhaveri, and 1 more authorIn Preprint, 2025Code-mixed languages, characterized by frequent within-sentence language transitions, present structural challenges that standard language models fail to address. In this work, we propose CMLFormer, an enhanced multi-layer dual-decoder Transformer with a shared encoder and synchronized decoder cross-attention, designed to model the linguistic and semantic dynamics of code-mixed text. CMLFormer is pre-trained on an augmented Hinglish corpus with switching point and translation annotations with multiple new objectives specifically aimed at capturing switching behavior, cross-lingual structure, and code-mixing complexity. Our experiments show that CMLFormer improves F1 score, precision, and accuracy over other approaches on the HASOC-2021 benchmark under selected pre-training setups. Attention analyses further show that it can identify and attend to switching points, validating its sensitivity to code-mixed structure. These results demonstrate the effectiveness of CMLFormer’s architecture and multi-task pre-training strategy for modeling code-mixed languages.
@inproceedings{roy2025llmstextitunderstandmath, title = {Can LLMs understand Math? -- Exploring the Pitfalls in Mathematical Reasoning}, author = {Roy, Tiasa Singha and Baral, Aditeya and Jhaveri, Ayush Rajesh and Baig, Yusuf}, booktitle = {Preprint}, year = {2025}, url = {https://arxiv.org/abs/2505.15623}, dimensions = {true}, }




2023
- Webex AI
 ChatBERT - Multi-task approach to Pre-Training for Structured ConversationsAditeya Baral, and Cisco SystemsIn Work done and published as part of Cisco Webex AI Research, 2023
ChatBERT - Multi-task approach to Pre-Training for Structured ConversationsAditeya Baral, and Cisco SystemsIn Work done and published as part of Cisco Webex AI Research, 2023The emergence of collaboration platforms in recent times has enabled users to communicate effortlessly across the world. Existing conversational modelling techniques do not learn accurate representations of structured conversations since they are primarily aimed at causal text generation in a one-to-one setting. Structured conversations, on the other hand, involve multiple turns and store metadata such as authorship, timestamps, membership, and other attributes. Causal language models only attend to previous tokens while generating the next token, which makes them fail at representing complex bidirectional relationships between concepts, authors and turns in structured conversations, which are essential for lanugage understanding and predictive tasks. In this paper, we propose a novel pre-training strategy for multi-turn dialogue modelling that leverages both conversational data and metadata. Our approach combines multiple supervised and unsupervised objectives to learn task and domain-agnostic representations to capture both semantics and structure of conversations. Experiments with our approach show that our language models can learn hierarchical relationships between dialogues, concepts and authors in conversations, which allow it to outperform existing conversational models on multiple downstream tasks.
@inproceedings{chatbert-baral-et-al-2021, author = {Baral, Aditeya and Systems, Cisco}, title = {ChatBERT - Multi-task approach to Pre-Training for Structured Conversations}, booktitle = {Work done and published as part of Cisco Webex AI Research}, year = {2023}, dimensions = {true}, }

2022
- AAAI-MAKE 2022
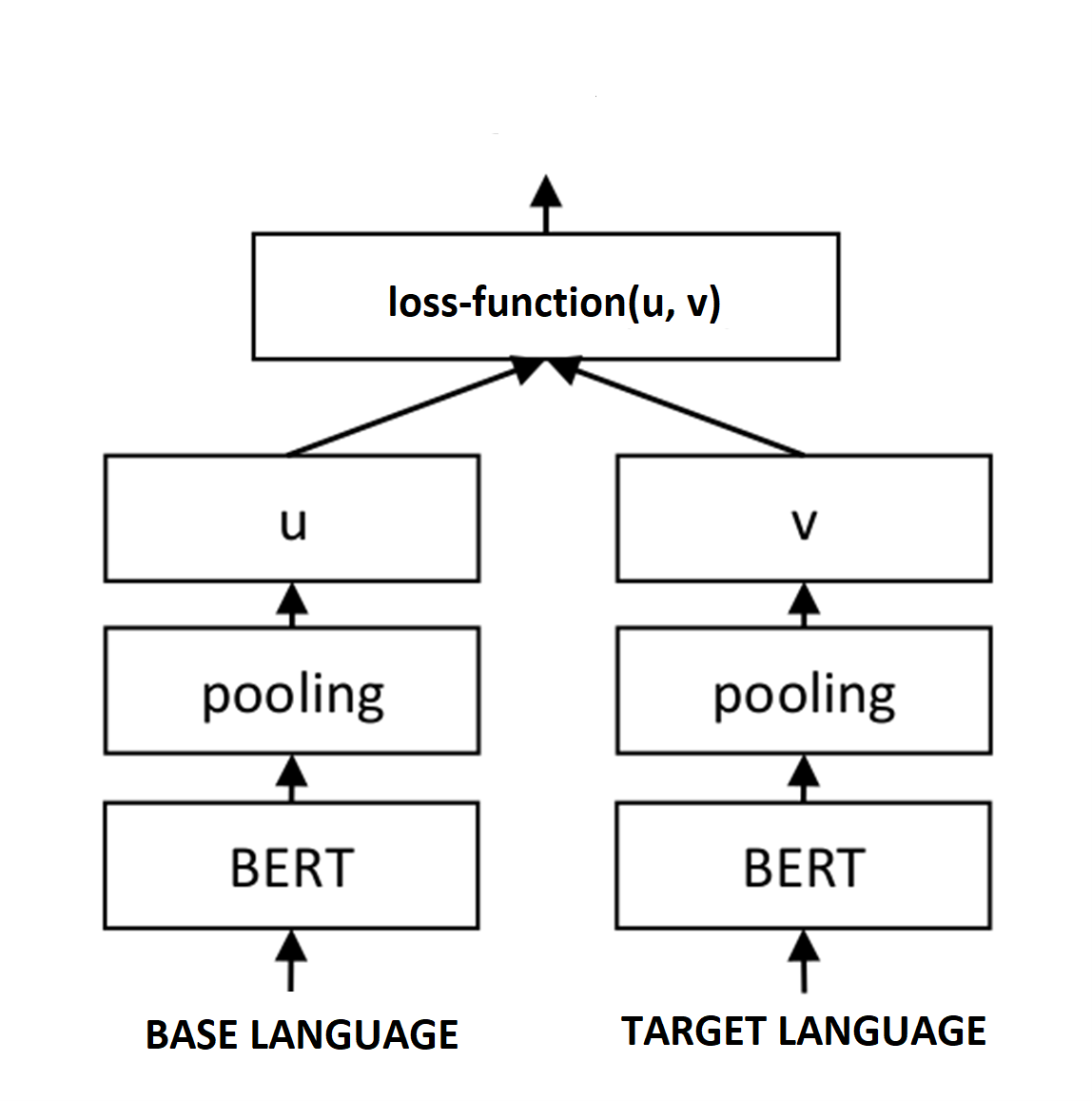 CalBERT - Code-Mixed Adaptive Language Representations Using BERTAditeya Baral, Aronya Baksy, Ansh Sarkar, and 2 more authorsIn Proceedings of the AAAI 2022 Spring Symposium on Machine Learning and Knowledge Engineering for Hybrid Intelligence (AAAI-MAKE 2022), Stanford University, Palo Alto, California, USA, March 21-23, 2022, 2022
CalBERT - Code-Mixed Adaptive Language Representations Using BERTAditeya Baral, Aronya Baksy, Ansh Sarkar, and 2 more authorsIn Proceedings of the AAAI 2022 Spring Symposium on Machine Learning and Knowledge Engineering for Hybrid Intelligence (AAAI-MAKE 2022), Stanford University, Palo Alto, California, USA, March 21-23, 2022, 2022A code-mixed language is a type of language that involves the combination of two or more language varieties in its script or speech. Analysis of code-text is difficult to tackle because the language present is not consistent and does not work with existing monolingual approaches. We propose a novel approach to improve performance in Transformers by introducing an additional step called "Siamese Pre-Training", which allows pre-trained monolingual Transformers to adapt language representations for code-mixed languages with a few examples of code-mixed data. The proposed architectures beat the state of the art F1-score on the Sentiment Analysis for Indian Languages (SAIL) dataset, with the highest possible improvement being 5.1 points, while also achieving the state-of-the-art accuracy on the IndicGLUE Product Reviews dataset by beating the benchmark by 0.4 points.
@inproceedings{calbert-baral-et-al-2022, author = {Baral, Aditeya and Baksy, Aronya and Sarkar, Ansh and D, Deeksha and Joshi, Ashwini M.}, editor = {Martin, Andreas and Hinkelmann, Knut and Fill, Hans{-}Georg and Gerber, Aurona and Lenat, Doug and Stolle, Reinhard and van Harmelen, Frank}, title = {CalBERT - Code-Mixed Adaptive Language Representations Using {BERT}}, booktitle = {Proceedings of the {AAAI} 2022 Spring Symposium on Machine Learning and Knowledge Engineering for Hybrid Intelligence {(AAAI-MAKE} 2022), Stanford University, Palo Alto, California, USA, March 21-23, 2022}, series = {{CEUR} Workshop Proceedings}, volume = {3121}, publisher = {CEUR-WS.org}, year = {2022}, url = {http://ceur-ws.org/Vol-3121/short3.pdf}, timestamp = {Fri, 22 Apr 2022 14:55:37 +0200}, dimensions = {true}, }

2021
- Intel (VSG) Research
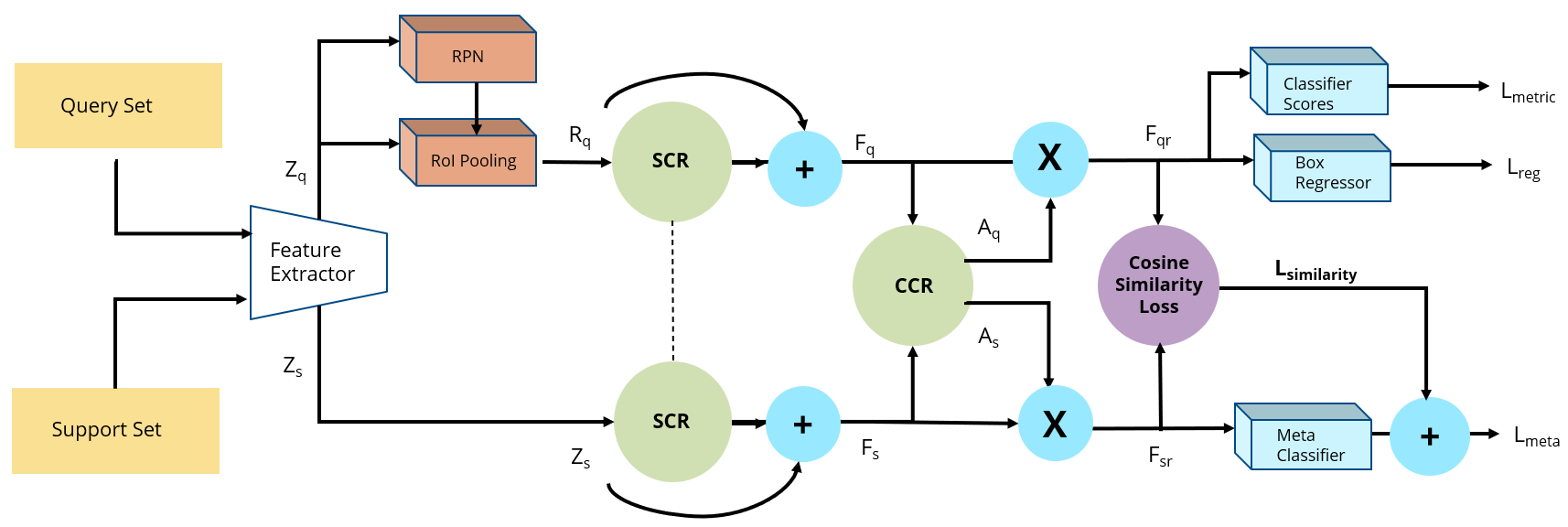 Information Maximization to Overcome Catastrophic Forgetting in Few-Shot Object DetectionAditeya Baral, Anay Majee, and Anbumani SubramanianIn Work done and published as part of Intel (VSG) Research, 2021
Information Maximization to Overcome Catastrophic Forgetting in Few-Shot Object DetectionAditeya Baral, Anay Majee, and Anbumani SubramanianIn Work done and published as part of Intel (VSG) Research, 2021Few-shot object detection encompasses the tasks of localizing and classifying objects in an image provided a limited number of training examples. Recent techniques in this domain suffer from confusion between object classes and demonstrate a tendency to forget the knowledge of already learnt classes, also known as catastrophic forgetting.Our work overcomes the impedance of catastrophic forgetting through an information maximization approach - Information Maximization Network (IMNet) that focuses on learning more descriptive feature representations without overfitting on irrelevant ones while retaining the relevant features from already learnt classes in an input image. Our introduced Cross-Entropy Similarity Loss decreases class confusion by adjusting the embedding space to allow homogeneous classes to have feature representations close to one another and heterogeneous classes to have a high separation between them. We conduct our experiments on the India Driving Dataset (IDD), which demonstrates a real-world setting alongside large class imbalance. Our IMNet architecture outperforms existing meta-learning approaches by 0.2 mAP on the base classes and up to 3 mAP on novel classes of IDD.
@inproceedings{imnet-baral-et-al-2021, author = {Baral, Aditeya and Majee, Anay and Subramanian, Anbumani}, title = {Information Maximization to Overcome Catastrophic Forgetting in Few-Shot Object Detection}, booktitle = {Work done and published as part of Intel (VSG) Research}, year = {2021}, dimensions = {true} } - ICNLSP 2021
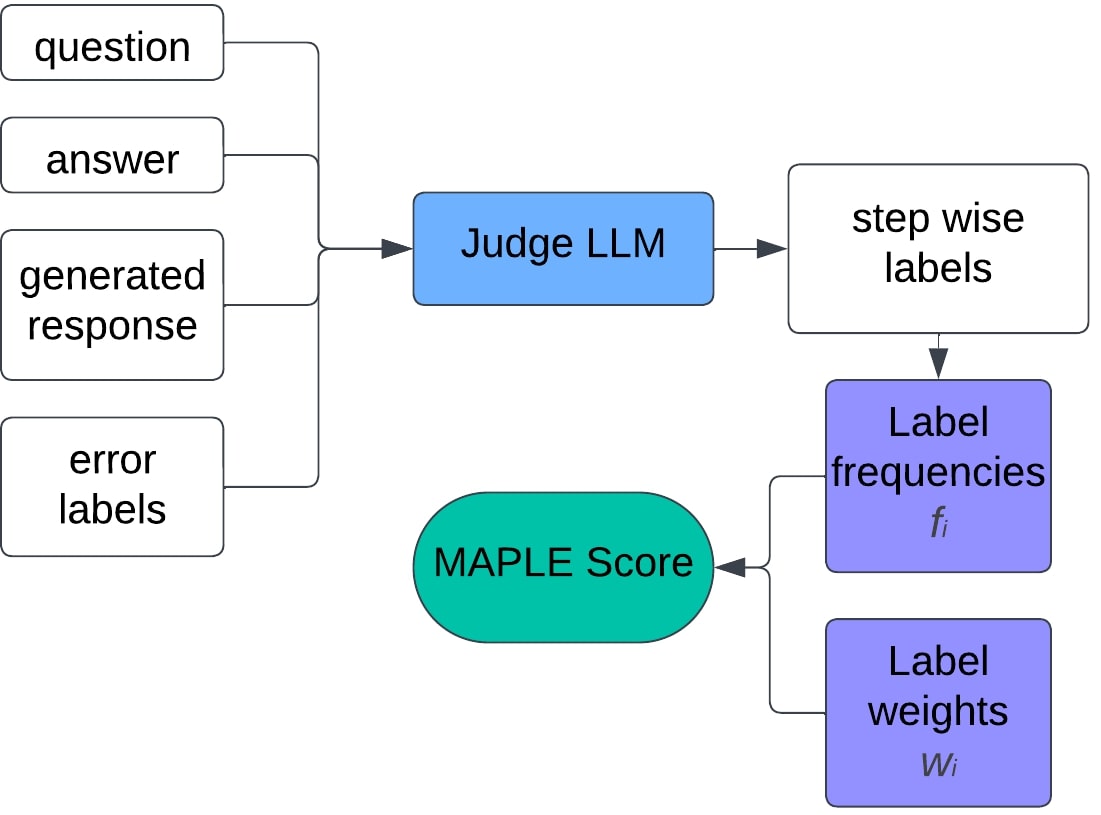
 MAPLE – MAsking words to generate blackout Poetry using sequence-to-sequence LEarningAditeya Baral, Himanshu Jain, Deeksha D, and 1 more authorIn Proceedings of the 4th International Conference on Natural Language and Speech Processing (ICNLSP 2021), Nov 2021
MAPLE – MAsking words to generate blackout Poetry using sequence-to-sequence LEarningAditeya Baral, Himanshu Jain, Deeksha D, and 1 more authorIn Proceedings of the 4th International Conference on Natural Language and Speech Processing (ICNLSP 2021), Nov 2021Poetry has morphed rapidly over changing times with non-traditional forms stirring the creative minds of people today. One such type of poetry is blackout poetry. Blackout poetry is a form of poetry in which words in a passage are masked, except for a few which when combined together in order to convey some meaning. With the recent developments in Natural Language Processing aiming to simulate human creativity, we propose a novel approach to blackout poetry generation employing deep learning. We explore four different architectures, namely an encoder-decoder with Bidirectional Long Short-Term Memory (LSTM) and Attention, a Bidirectional LSTM Conditional Random Fields (LSTMCRF) architecture, Bidirectional Encoder Representations from Transformers (BERT) and Robustly Optimized BERT Pre-training Approach (RoBERTa). The first architecture employs abstractive summarization and the remaining employed sequence labelling to generate poetry. The Transformer based architectures prove to be the best working models, and were also able to pass a Turing Test as well.
@inproceedings{maple-baral-etal-2021, title = {{MAPLE} {--} {MA}sking words to generate blackout Poetry using sequence-to-sequence {LE}arning}, author = {Baral, Aditeya and Jain, Himanshu and D, Deeksha and R, Dr. Mamatha H}, booktitle = {Proceedings of the 4th International Conference on Natural Language and Speech Processing (ICNLSP 2021)}, month = nov, year = {2021}, address = {Trento, Italy}, publisher = {Association for Computational Linguistics}, pages = {47--54}, dimensions = {true}, } - IEEE CONIT 2021
 Analysis of Kepler Objects of Interest using Machine Learning for Exoplanet IdentificationAmeya Rajendra Bhamare, Aditeya Baral, and Saarthak AgarwalIn 2021 International Conference on Intelligent Technologies (CONIT), Aug 2021
Analysis of Kepler Objects of Interest using Machine Learning for Exoplanet IdentificationAmeya Rajendra Bhamare, Aditeya Baral, and Saarthak AgarwalIn 2021 International Conference on Intelligent Technologies (CONIT), Aug 2021For several decades, planet identification has only been performed by astronomical experts and researchers with the help of specialized equipment. With the advent of computational methods and access to satellite data from space missions, this trend has changed. For instance, NASA’s Exoplanet Exploration program has provided us vast amounts of data on celestial objects to assist in space exploration. One such mission of interest is the Kepler mission. Over 4000 such transiting exoplanets have been identified since the mission commenced in 2007. It has provided us with an extensive database of discoveries that help in computing planet occurrence rates as a function of an object’s parameters such as the size, insolation flux, star type and orbital period. This information is catalogued in the Cumulative Kepler Object of Information dataset. Four basic models have been compared. Namely, Support Vector Machines, Random Forest Classifiers, AdaBoost and Deep Neural Networks. The AdaBoost classifier was selected as the optimum machine learning model and returned an F-1 score of 0.98.
@inproceedings{kepler-bhamare-etal-2021, author = {Bhamare, Ameya Rajendra and Baral, Aditeya and Agarwal, Saarthak}, booktitle = {2021 International Conference on Intelligent Technologies (CONIT)}, title = {Analysis of Kepler Objects of Interest using Machine Learning for Exoplanet Identification}, year = {2021}, month = aug, pages = {1-8}, dimensions = {true}, }


